I have a folder with 2700 pdf’s. In each of them are several photos’ from an item. An AI needs to write 5 lines of text which will be used on a Shopify website.
Hey @Donna! If you’re reporting an issue with a flow or an error in a run, please include the run link and make sure it’s shareable so we can take a look.
Find your run link on the history page. Format: https://www.gumloop.com/pipeline?run_id={{your_run_id}}&workbook_id={{workbook_id}}
Make it shareable by clicking “Share” → ‘Anyone with the link can view’ in the top-left corner of the flow screen.
Provide details about the issue—more context helps us troubleshoot faster.
Hey @Donna – Can you share the run link where it’s not working please so I can view the inputs/outputs. From your screenshot I can see that the Analyze Image node has an empty input field.
No problem! Would it be possible to separate these files in smaller folders? I think that’d be the best solution. With the List Trimmer the Google Drive Folder Reader node would always run first and read all 2.7k files.
Another option is to export all the drive links to a spreadsheet and read 50 rows at a time from that and use the Use Link option on the Drive File Reader node.
Ah sorry, should’ve clarified — this would be outside of Gumloop, done via an app script. I’m assuming it’s a one-time large batch run, which is why I made the suggestion. If that’s not feasible, then using separate folders is probably your best bet if you’re looking for efficiency in the flow without having to read all files each time.
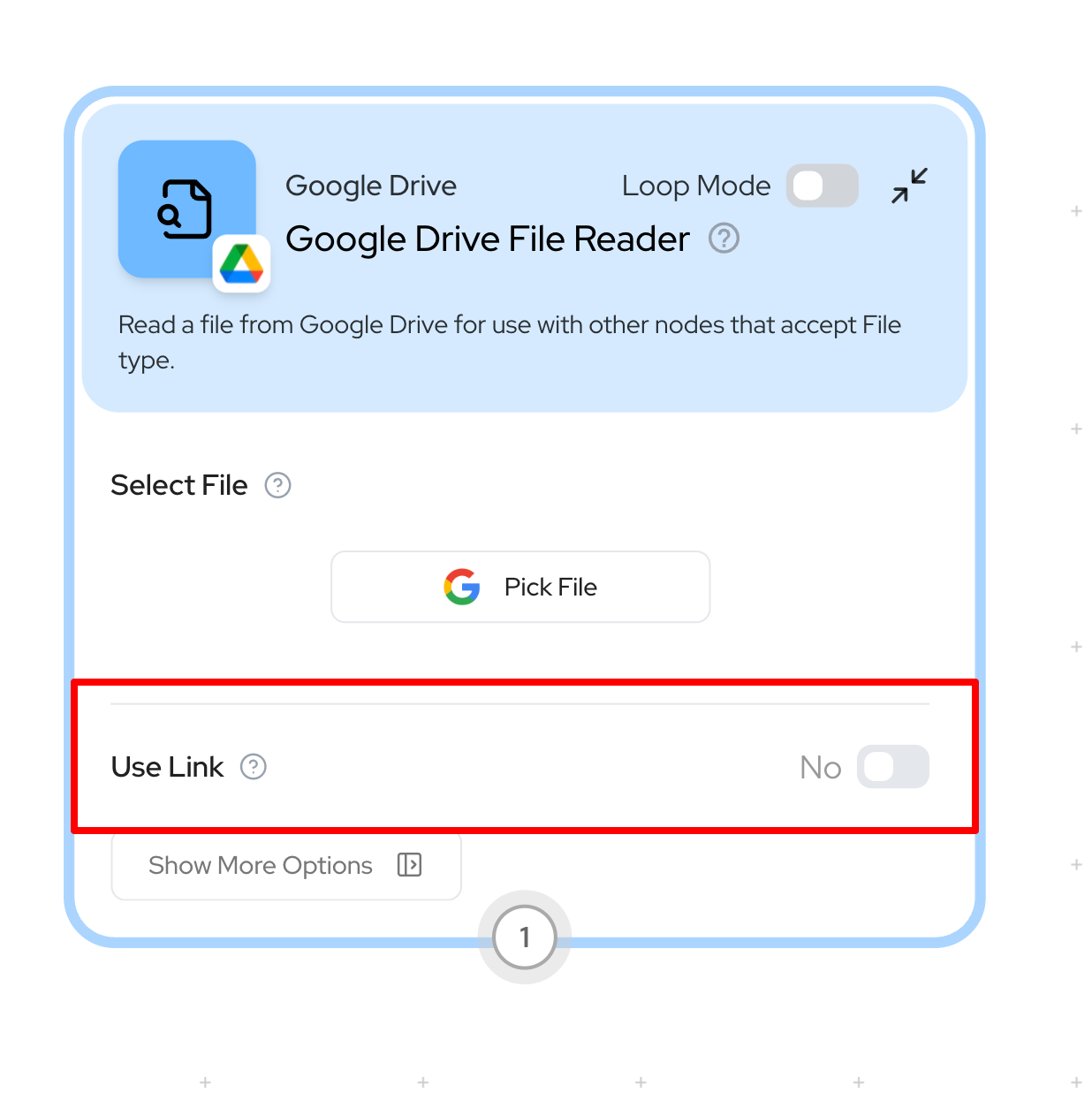
You’re passing the spreadsheet link here instead of the drive link. You should just enable Use Link manually in the node (instead of populating it dynamically) and then feed the Drive Link from your spreadsheet in the Link input not the Use Link input. The Use Link option is a parameter on the node, the toggle that you see here:
Looking at the forum I think it will be a good idea to write one dedicated blogpost about all possibilities and potetial issues about Google Drive Folder reader, File reader, sheets, links, file creation etc etc With use cases
Instead of you having to reply to all different flavours of questions (because it is still a bit confusing)