https://www.gumloop.com/pipeline?workbook_id=iNecYLsWMBvENfRBHHoJqS&run_id=BuaWqdaA68VhkMDoeu8ck2
https://www.gumloop.com/pipeline?workbook_id=iNecYLsWMBvENfRBHHoJqS
I’m building an automation that:
- Monitors a Google Drive folder for new meeting transcript files
- Analyzes the transcript to identify ALL problems discussed
- Creates structured problem briefs with names and descriptions
- Emails these problems briefs (eventually will create Basecamp projects) in the correct lines e.g., problem name 1, description 1, name 2, description 2, etc.
Current Issue
My flow fails with this error:
Invalid Google Drive file link or ID. A proper Google Drive file link must start with 'https://drive.google.com/file/d/'
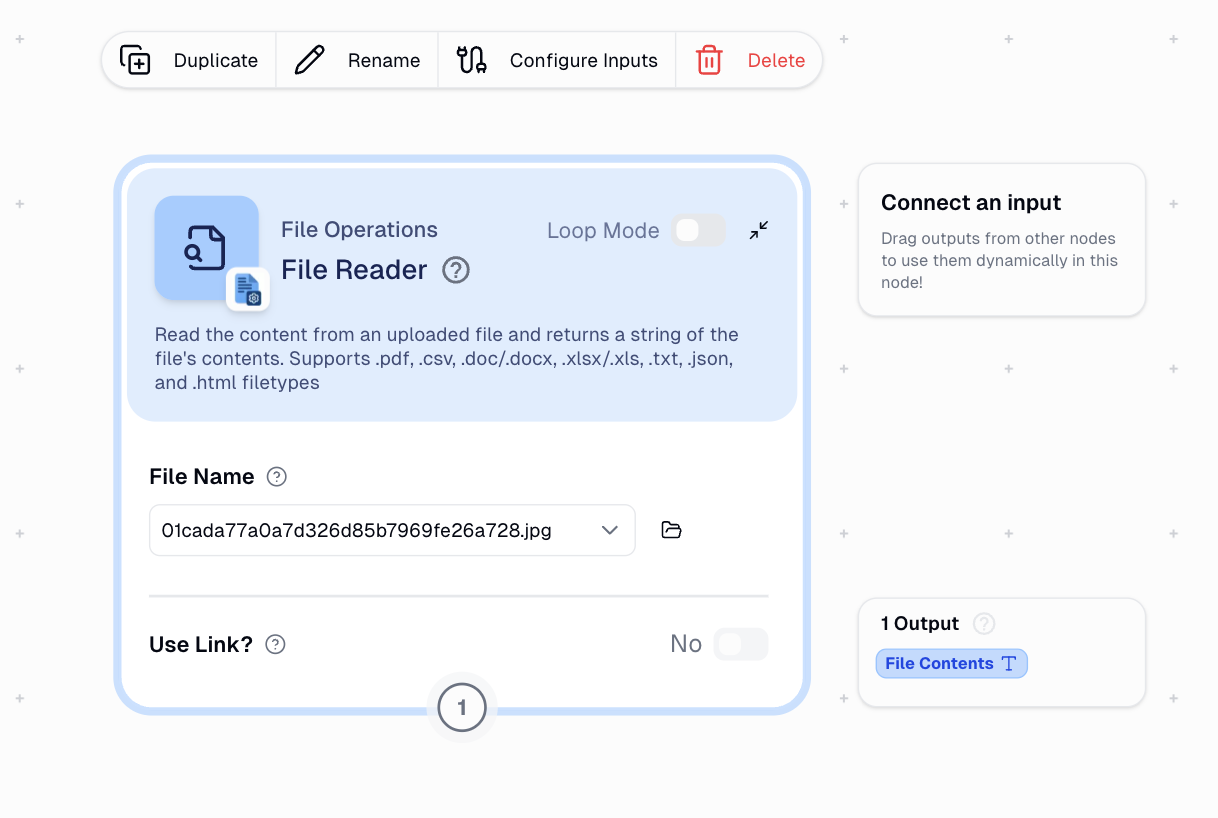
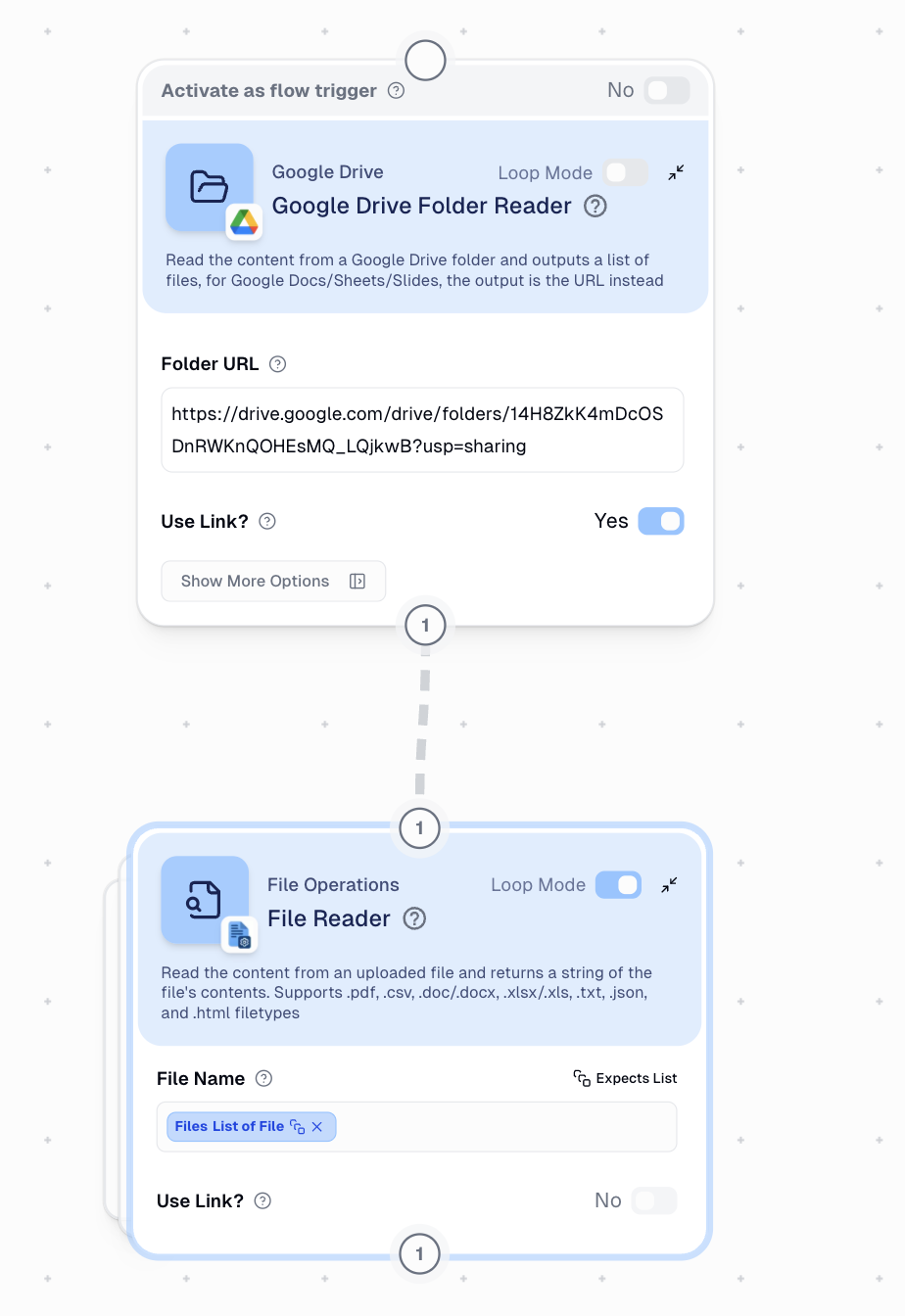
The Google Drive Folder Reader successfully finds files, but the Google Drive File Reader can’t process the file format it receives.
My Current Flow Structure
- Google Drive Folder Reader - Monitors a specific folder for transcript files
- Google Drive File Reader - Attempts to read the file contents but fails
- Join List Items - Combines file contents into one text
- Chunk Text - Splits text into manageable chunks
- Extract Data - AI analyzes text to identify problems and descriptions
- Flatten List of Lists - Processes the extracted data
- Combine Text - Formats problems and descriptions
- Gmail Sender - Sends email with the analysis results
What I’ve Tried
- Checked the Google Drive Folder Reader configuration
- Verified the file format in Google Drive
- Added Error Shield to catch failures
- Tried different connection configurations
Questions
- How do I correctly connect the Google Drive Folder Reader to the File Reader?
- Is there a specific format needed for the file links?
- Should I be using a different approach to read the file contents?
- Are there any example flows that successfully read and process Google Drive files?
- Is there anything I’m missing to ensure this runs properly?
Any help would be greatly appreciated! I’m trying to automate our weekly meeting follow-ups to ensure no problems slip through the cracks.