I’m running a workflow where I’m taking company names from a Google sheet, running AI deep research to filter them into one of two categories, and outputting the categorization results to the Google sheet.
On any given run, about 20% of these will not reach the final stage for some reason. I have error shields to prevent this from ending the run, but I end up with some companies that haven’t been categorized.
The problem is that when I try to run the workflow again with just those categories, it refuses to run them. I click “Run” and it instantly completes the processing for all of the companies, and I don’t get an output for these companies.
I assume the workflow remembers that it has already run these companies and skips running the full workflow for them again. I’m not sure how to disable this behavior, though.
Sometimes if I add extra characters to the company name (to make it a unique string again) it works, but that’s not 100%. It’s also quite annoying to do that.
Hey @srst! If you’re reporting an issue with a flow or an error in a run, please include the run link and make sure it’s shareable so we can take a look.
Find your run link on the history page. Format: https://www.gumloop.com/pipeline?run_id={{your_run_id}}&workbook_id={{workbook_id}}
Make it shareable by clicking “Share” → ‘Anyone with the link can view’ in the top-left corner of the flow screen.
Provide details about the issue—more context helps us troubleshoot faster.
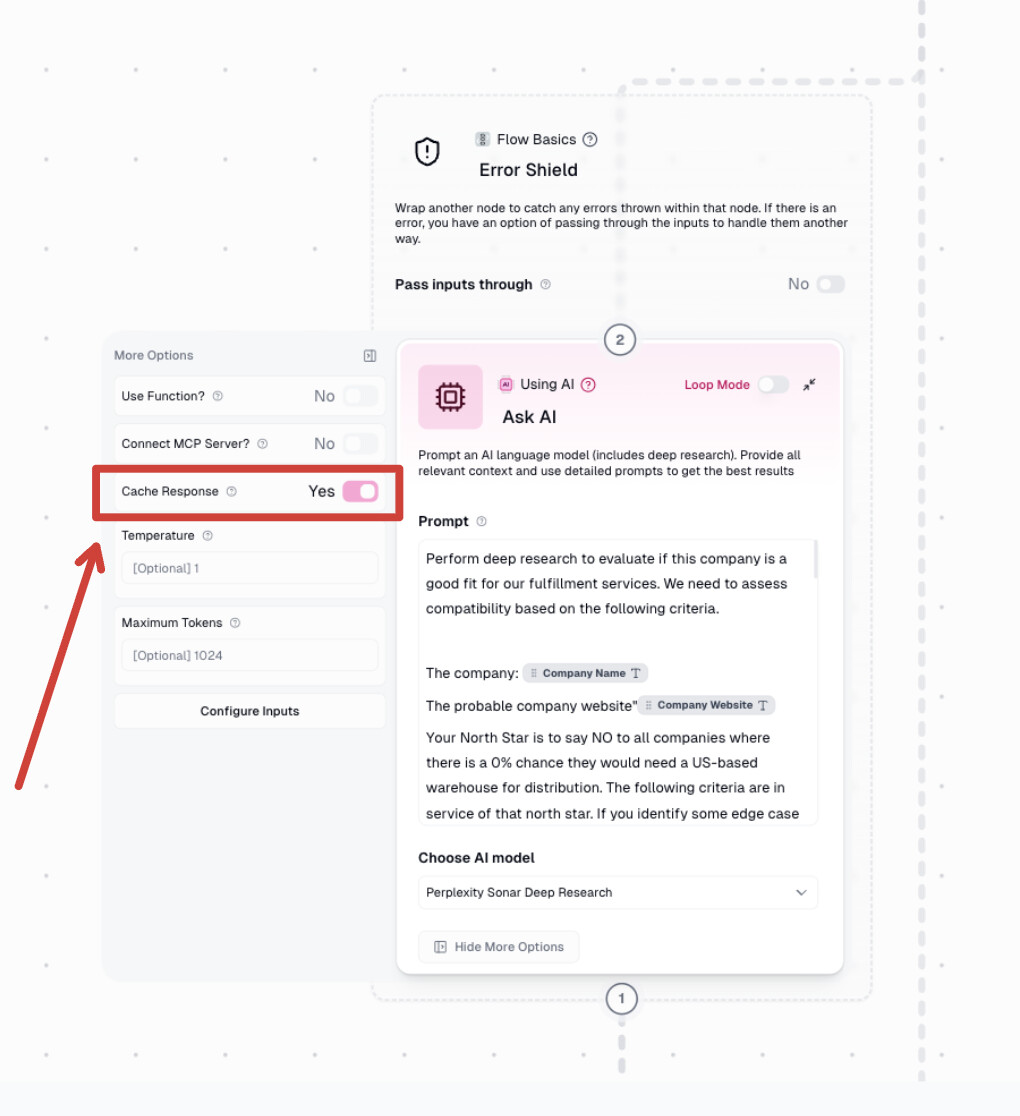
Hey @srst, thanks for sharing the details! What you’re seeing happens because AI nodes use caching by default. If the same input is sent again, the flows skips reprocessing to save credits — which is why your reruns finish instantly.
To fix this, open the AI node, click More options, and turn off Cache response. That will force a fresh run every time.
Also, I noticed your Categorizer node currently only has one category right now. If you want a proper Yes/No result, you would have to add both categories.
Hey @srst, I took a look at your past runs and can confirm that caching is disabled. I also see the inputs are being reprocessed each time (I’ve attached an image for reference).
Could you point out where you’re still noticing similar outputs? If you can share specific run links, that’ll make it easier to compare. In general, with caching off, the Ask AI node should generate at least some variation in its output each time it runs.